Parse.ly Recommendation Engine Explainer (part 2): Under the Hood
In my last post on this topic, I introduced Parse.ly’s recommendation engine. There, I discussed how our recommendation engine for digital media websites takes a content-driven approach; supports contextualized and personalized modes of operation; and is exposed through four simple HTTP/JSON endpoints. In this post, we’ll go under the hood on the recommendation engine to understand how it works, and why it works so well.
It Starts With Engagement Data
In order to power Parse.ly’s real-time and historical dashboards, Parse.ly collects engagement data from websites, which includes metrics around views, visitors, engaged time, and shares.
Website owners send engagement data to Parse.ly by integrating our JavaScript code on their site. Visitors and views to URLs are captured via pageview events, and engaged time is captured via periodic heartbeat events. A single 60-second visit to an article page might result in one initial pageview event to Parse.ly, followed by six or so heartbeat events, each indicating approximately 10 seconds of activity (or “dwell time”) on the page.
This engagement data is quite rich. Here is a snippet of our data as it gets exposed to customers via our Raw Data Pipeline. Note: for simplicity of illustration, I’ve elided many fields from this listing. In this case, we’re looking at a single page view event, from a mobile device clicking from Facebook over to The New Yorker’s Pulitzer Prize-winning piece on the San Andreas earthquake fault line, entitled “The Really Big One”.
{
"action": "pageview",
"apikey": "newyorker.com",
"referrer": "...m.facebook.com/",
"ts_action": "2016-04-30 17:45:03",
"url": "...newyorker.com/magazine/2015/07/20/the-really-big-one",
"user_agent": "... Chrome/49.0.2623.105 Mobile Safari/537.36",
"visitor_site_id": "dec4bd83-286c-4f5c-9b67-5f8070759e3d"
}
From this engagement data, we’ll later be able to prioritize results from our recommendation calls by these signals.
Under the hood, our real-time data pipeline is implemented using Apache Kafka and Apache Storm, two technologies we support through open source contributions. We are the maintainers of the pykafka and pystorm libraries, which integrate Python with these tools. We also created streamparse, which is a stream processing development framework built atop pystorm.
Viewed URLs Get Crawled and Enriched
Every time a user views a page, Parse.ly’s backend systems understand this is a potentially interesting piece of content. Upon the first view of a page on-record for Parse.ly, a web crawler is dispatched to download interesting information about the page.
To support article metadata and text extraction, Parse.ly invested in expertise around the Scrapy project, among other open source web crawling-related projects, such as newspaper. We also collaborated with the rNews group and the Google AMP team, which has centered around the http://schema.org/NewsArticle standard. Finally, we guide sites to adopt metadata standards by integrating our metadata tag.
So, how does Parse.ly metadata look for The New Yorker article above?
{
"apikey": "newyorker.com",
"title_en": "The Really Big One",
"full_content_en": "When the 2011 earthquake ..."
"authors": ["Kathryn Schulz"],
"tags": [
"cascadian fault",
"seismology",
"fault lines",
"earthquakes"],
"section": "Magazine",
"pub_date": "2015-07-13T04:00:00",
"image_url": "...newyorker.com/...10165805.jpg",
"url": "...newyorker.com/magazine/2015/07/20/the-really-big-one",
}
Which you can think of as the “machine representation” of the kind of metadata that describes the article as you see it on the website. I’ve elided the full contents of several fields here.

Here are a couple of interesting things about this article:
- Parse.ly detects that it’s an English-language article, and analyzes it appropriately. Thus the special fields,
title_enandfull_content_en; theenstands for “English”. Parse.ly’s text analyzer supports over 30 languages. - The
pub_datefield allows us to do smart filtering based on publication time. - The
authors,section, andtagsallow us to do exact matches to other related archive pieces automatically. It’s written by Kathryn Schulz, who is actually a prolific author on the website. - Analyzing the article headline (“The Really Big One”) would not be nearly enough to understand what this article is about! We index the full content for the article, which includes over 14 printed pages of text (thousands of words). This gives our system a much better idea.
“Related” Means Matches and Relevancy
All told, this gives us lots of clues to make a very solid — yet still 100 percent automatic and algorithmic — content recommendation. For example, our recommender suggests the story, “How to Stay Safe When the Big One Comes”, a follow-up story written by the same author a month later, talking about many similar topics. This is a solid recommendation — but our recommender also finds subtler connections to other stories, too.
For example, our recommender surfaces the more-recently-published “The Rise and Fall of Onagawa”, a story written about Japanese earthquakes, whose primary locale was also a topic of interest in the original story. Though it was not written by the same author nor tagged the same way, and was published over a year a later, our recommender is able to find this connection and draw users to this related content.
Even better, this connection is bi-directional: the recently published post can recommend the original Pulitzer Prize-winning piece by Kathryn Schulz, even though the author of the new piece did not mention her or the San Andreas fault line, and even though the new piece does not link to the old piece! That’s the power of “algorithmic serendipity”.
Under the hood, this is all powered by Lucene and Elasticsearch, important technologies for us here at Parse.ly. You can check out our in-depth post on the magic of Lucene, entitled “Lucene: The Good Parts”.
Training User Profiles for Personalization
So, we’ve learned how Parse.ly’s API can help us automatically lay connections between posts. Now, let’s learn how it can assist with completely personalized experiences.
To make personalization work, Parse.ly requires the use of one more endpoint: /profile. By firing a request against /profile, customers can “train” a personalized user profile for a given piece of content. What does it mean to “train” a profile? Well, you are telling Parse.ly that a certain user has “read” or is otherwise “interested” in this story.
Why don’t we automatically train stories based on clicks? Well, there are quite a few reasons:
- Sites might have a UUID that is more reliable than Parse.ly’s. Ours is based on a first-party cookie set at the domain level, and these cookies can sometimes be cleared by users. If your site supports login or social login, you may want to use your own internal identifier instead.
- Some sites don’t equate “very short views” with “interest”. For example, some sites only register a
/profilecall after at least 10 seconds of activity on the page, since less than that is more like a “bounce” than a “view”, and thus shouldn’t be considered a positive signal. - Some site operators like the idea of only training articles that have been explicitly “liked”, “saved”, or “shared” — depending on whether these actions are available on a site-by-site basis. This gives them that flexibility.
- Some site operators only want to enable personalization for a subset of users, e.g. logged in users or users who are clicking through from the homepage.
That said, Parse.ly’s automatically-generated UUID is available to you, if you want to make use of it. We have it available as a JavaScript API property called PARSELY.config.uuid, as described in our recommendation example documentation, which also includes a recipe to do recommendations based solely on our anonymous identifier.
So, what does it mean, from Parse.ly’s standpoint, when you train a URL again a UUID? Well, Parse.ly will do the following:
- Look up that URL to find a matching crawl record (described above)
- Train all the structured attributes against the user profile, e.g. “this user is interested in this author, this section, these tags”
- Train all the unstructured topical data against the user profile, e.g. “this user is interested in politics and culture, but not sports; has a particular interest in articles about Washington U.S. politics.”
- In all cases, each training action will also have a timestamp associated with it
Now, when a uuid is used as a parameter to the /related endpoint, we will rewrite the user profile as a query to find related content personalized just for that user.
Rewriting Profiles as Queries
What does it mean to rewrite a user profile as a query? Well, consider the following steps taken by a specific user:
- She read “The Really Big One” on NewYorker.com yesterday evening
- Early this morning, she went to The New Yorker homepage and read a story by Jonathan Franzen, “The End of The End of the World”
- Just a few minutes ago, she clicked back to The New Yorker’s site from Facebook via a thinkpiece on, well, Facebook, entitled “Why Do We Care If Facebook Is Biased?”
What stories should we show this user? Well, Parse.ly gives our customers choices. If they are using a personalization strategy based on the user’s UUID, we will pick some of the stories from the archive that are related to earthquakes, science, and the authors trained in steps 1 and 2 (Kathryn Schulz and Jonathan Franzen). But if we use a contextual approach, we can only use information about the story in step 3, which means that even though we know the user is interested in those other topics, we’ll only recommend stories about Facebook and technology.
The way we achieve the personalization is by rewriting the user’s “interest profile” as a query with various parameters set and tuned. For example:
- We hide all visited stories — the stories the user read in 1 and 2 will not be present in their list of recommendations, as users typically do not want to re-read stories they have already read
- We would weight a Jonathan Franzen story over a Kathryn Shulz one, all things being equal — this is because the Franzen story was read more recently, and we weight our results by their relevancy to our most recent trained articles
- If we could not find a good Franzen story, it’s very likely we’d find a good, related Schulz or earthquake story — even though this user only read about earthquakes via Schulz a few clicks ago!
Choosing the best way to map user profiles into related content queries is both an art and a science, but something that Parse.ly is continuously measuring and tuning.
Turning Knobs with Filters and Strategies
We are coming near the end of our explanation of our recommender. Before we close with a discussion of recommendation performance, we will talk about the system’s configuration options for tuning recommendations.
There are various knobs available to customers, as described in our official documentaiton. For example, you can:
- Exclude certain sections, authors, or tags from results
- Filter results by published date
- Sort by results from social, search, or internal traffic
This can be used to exclude sponsored content, control recommendation content freshness, or leverage Parse.ly’s engagement data to weight recommendation results toward those “voted on” by your broad audience (via clicks on social, search, or from your own front pages). By tweaking these parameters, you can bring Parse.ly’s API over that last mile to deliver the results your audience needs. We highly recommend site operators look over these options, as often a “stock” integration can be enhanced by simply tweaking a few parameters.
Running Fast
Our final topic will be performance — that is, speed.
Parse.ly’s recommendation engine is not only comprehensive and powerful, but also lightning fast. This is important because often recommendations are rendered upon every page view on high-traffic sites.
We employ a number of strategies to make our recommendations fast, but what it most importantly comes down to is scale. Since we run a content recommendation engine that gets over 2 billion API calls per month, we have invested in a distributed infrastructure that allows us to return results with tight latencies to all customers. Our recommendation cluster is spread over 40 nodes in three data centers, and we continuously expand the cluster to meet load requirements.
But it’s not just scale. We also employ speed-enhancing technologies, such as Varnish, Redis, and Tornado. This ensures repeated calls to our API are automatically cached, and those that can’t be cached are nonetheless returned very quickly.
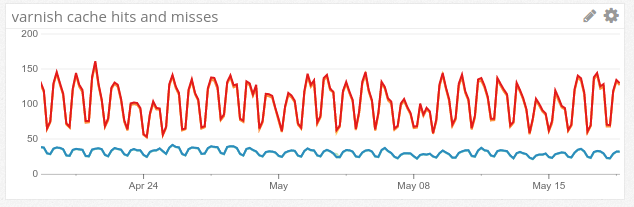
So, at the flip of a switch and with zero ops work, you are using an optimized stack for recommendations that is already trusted by — and scaled for — some of the web’s highest traffic sites. How awesome is that?
I hope you’ve enjoyed this two-part explainer on Parse.ly’s recommendation engine. If you have more questions, feel free to reach out on Twitter via @amontalenti or @parsely. And if you are already a Parse.ly customer and want to use our API on your site, simply open up a support ticket and we’ll be in touch!