PyKafka: Fast, Pythonic Kafka, at Last!
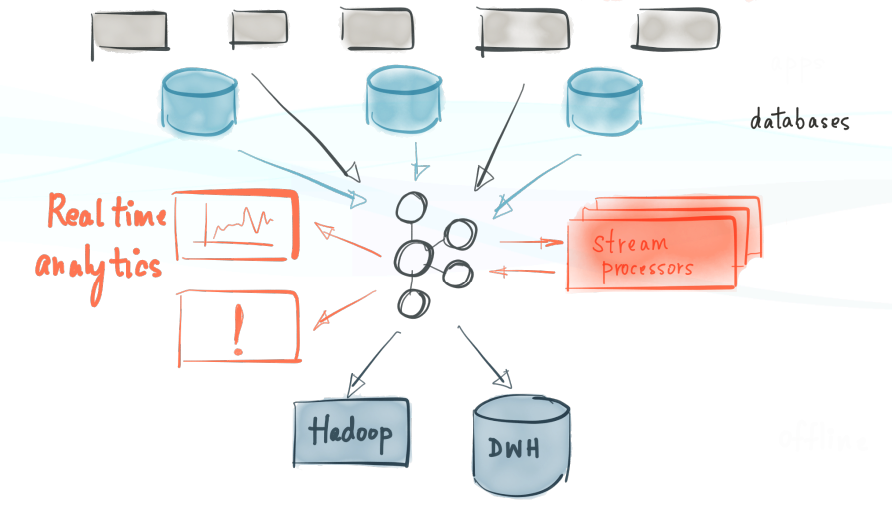
Why Parse.ly uses Kafka
For the last three years, Parse.ly has been one of the biggest production users of Apache Kafka as a core piece of infrastructure in our log-oriented architecture. We currently process over 90 billion events per month in Kafka, which streams the data with sub-second latency in a large Apache Storm cluster. Data that originates in Kafka eventually finds its way into Mage, our time series analytics engine.

Apache Kafka is an open source distributed pub/sub messaging system originally released by the engineering team at LinkedIn.
Though using some variant of a message queue is common when building event/log analytics pipeliines, Kafka is uniquely suited to Parse.ly’s needs for a number of reasons. Specifically:
- Ridiculous write performance: Most people adopt Kafka because of this killer feature — you can send it gigabytes of data per second and you will always saturate your Kafka broker’s network card before saturating disk or CPU.
- Multiple consumers per topic: Traditional pub-sub systems make “fan-out” delivery of messages expensive; in Kafka, it’s nearly free. This means we can have multiple production, staging, and beta environments all reading production data without duplicating our raw data storage.
- Cluster-level fault tolerance: Kafka has a distributed design that replicates data per-topic and allows for seamless handling of individual node failure.
- Data retention for message replay: Kafka has a unique “distributed commit log” design to its topics, which makes it possible to replay old messages even if they have already been delivered to downstream consumers. This allows for various data recovery techniques that are typically unavailable in pub-sub systems.

Kafka is built around the notion of producers and consumers. Producers write messages to topics, and consumers read messages from those topics. This many-to-many message delivery architecture leads to a high level of production flexibility in moving data from point-to-point.
To leverage these features well, you need a good driver for your programming language of choice. Kafka is written in Scala and is thus a JVM-based technology, and includes high-quality Java-based drivers. However, Parse.ly is firmly a Python shop. We were already maintaining streamparse, a Python and Apache Storm integration library, so we figured it might be good to contribute our work on Kafka to the community, as well.

Releasing PyKafka 1.0 in 2015
Good Python drivers for Kafka really did not exist, even as late as June 2015. Though there was some code in the community, there was a huge lack of support for a specific Kafka usage pattern called “balanced consuming”. So, we took our internal code for this that we were already using in production, and we released it as PyKafka 1.0.
That open source release was successful beyond our wildest imagination. We received many community reports of production usage, including at organizations like the Wikimedia Foundation and Activision. Meanwhile, Parse.ly’s production usage of PyKafka continued to grow.

Click above to view how we scaled Kafka usage over time. Parse.ly started using Kafka in mid-2013, switching from a ZeroMQ-based architecture. This was right as our data volumes started to grow rapidly. By January 2014, we were processing 5 billion events per month in Kafka. One year later, we grew 300% to 15 billion events per month. The next year, we grew 600% to 90 billion events per month. Meanwhile, in the last 2.5 years, we have developed PyKafka, our production-strength Python driver for Kafka consumers and producers, in the open on Github. It now has 2,000+ commits and 320+ stars, and we’ve closed 300+ issues for the community.
In 2015, we also enlisted the help of Yung-Chin Oei, to join the existing PyKafka committers of Emmett Butler and Keith Bourgoin, in improving the project. Yung-Chin developed some initial support for bridging Python to librdkafka, a C-based driver for Kafka that boasted better performance, and his main project was to bring this support to PyKafka.
In the rest of this post, Yung-Chin will introduce PyKafka’s new APIs, explain his work on integrating librdkafka, and showcase some performance numbers he recorded on using Python and Kafka together with PyKafka.
Yung-Chin’s discovery of Kafka
It was sometime in 2014 that I first stumbled onto Kafka, and found Jay Kreps’ really rather lucid essay “The Log: What every software engineer should know about real-time data’s unifying abstraction”.
To my (admittedly historical-perspective-challenged) mind, it read as a founding text for a new paradigm in messaging systems. And if that was the first thought, of course the next one was “How do I talk to this from Python?”
At the time, the options were limited. There was kafka-python, which wasn’t very mature yet, and there was another project called samsa, which was however stuck on an old Kafka protocol version. A bit of a barren landscape.
But a lot can happen in a few months: Parse.ly released PyKafka, and started what was essentially a rewrite that brought it up to date supporting the Kafka 0.8.2 protocol. Best of all: they got me to contribute, too.
Basic pykafka usage
PyKafka basically aims to deal with all the particulars of talking to a Kafka cluster. Abstractly, all you need to do is tell it which “topic” your messages need to be sent to or retrieved from, and it will figure out which brokers to talk to, and will also handle any reconnections, cluster reconfigurations and retrying requests. But let’s see all that in code.
PyKafka’s API is organized so that most everything elegantly flows from a single entrypoint, a KafkaClient instance:
from pykafka import KafkaClient
client = KafkaClient("localhost:9092")
From there, you can discover available Kafka topics (try print client.topics) and then obtain a producer or consumer instance:
topic = client.topics["topicname"]
producer = topic.get_producer()
consumer = topic.get_simple_consumer()
(More on why it’s called a “simple” consumer later on.) Should you wish to explore low-level cluster details, you can dive into client.cluster or client.brokers, but for today we’ll stick to the higher-level subjects of producing and consuming messages.
Producing to Kafka
“Producing” is Kafka’s term for writing or sending a message to a topic. At its simplest, all it takes is this:
producer = topic.get_producer()
producer.produce(b"your message")
For the finer points, there are two things worth touching upon: message partitioning, and asynchronous usage patterns. Or wait — maybe three things.
If your application is suited for it, the producer can be used as a Python context manager, like so:
with topic.get_producer() as producer:
while not your_app.needs_stopping:
producer.produce(your_app.generate_interesting_message())
This will ensure that, upon exiting the context, the program waits for the producer to flush its message queues.
“Wait, what message queues?”, you ask. “You didn’t mention queues before!” Right, that gets me to the second thing. What’s important to know here, is that by default produce() ships your message asynchronously. This is important for performance — specifically, for throughput. PyKafka groups messages into batches in the background, which helps to reduce overhead and load on the Kafka cluster, and allows your application to charge ahead rather than block on network I/O. However, it also means that when produce() returns, you’ve no idea whether your message made it to disk on the cluster yet.
You have two options here. If you can afford produce() blocking until message delivery, the simplest thing is to start your producer in synchronous mode:
producer = topic.get_producer(sync=True)
In sync mode, either produce() returns and you know all is fine, or it raises an error. But, this is slow.
Even in sync-mode, if you produce() from multiple threads concurrently, those messages may still be batched together. It’s just that each of the producing threads will block waiting for delivery of the batch. This is a nice feature on, say, a multi-threaded webserver.
The other option is to enable delivery reports:
producer = topic.get_producer(delivery_reports=True)
In this mode, the producer instance exposes a queue interface on which it posts “delivery reports” for every message produced. You’re then expected to regularly pull the reports from the queue:
msg, exc = producer.get_delivery_report(block=False, timeout=.1)
If exc is not None, delivery failed and you can inspect the msg object which carries the message and its partitioning key. The idea here is that you can produce your messages fast (perhaps at rates of thousands per second), and then periodically check the delivery reports to make sure all the messages made it “to the other side” without errors.
That brings me to the last bit I want to highlight here: message partitioning. By default, messages are randomly allocated to topic partitions, but if you add a message key to your messages, and define a custom partitioner, you can achieve any allocation you like.
As an example, pykafka.partitioners.hashing_partitioner ensures that messages with a particular key consistently end up on the same partition:
producer = topic.get_producer(partitioner=hashing_partitioner)
producer.produce(b"your message", partition_key=b"bravo")
producer.produce(b"another message", partition_key=b"bravo")
will send both to the same topic partition.
So that’s producing in a nutshell. How do we get these messages back out?
Consuming messages with PyKafka
This can be as simple as
consumer = topic.get_simple_consumer()
msg = consumer.consume()
print("%s [key=%s, id=%s, offset=%s]" %
(msg.value, msg.partition_key, msg.partition_id, msg.offset))
That’s it. You pulled a message from the topic, and can now unwrap the payload and message key, and find out what partition it came from (because we didn’t specify otherwise, the consumer will read from all partitions that exist in this topic), and at what offset within the partition it sits.
Instead, you can also iterate over the consumer:
consumer = topic.get_simple_consumer(consumer_timeout_ms=5000)
for msg in consumer:
print(
"%s [key=%s, id=%s, offset=%s]" %
(msg.value, msg.partition_key, msg.partition_id, msg.offset))
Iteration stops if no new messages have become available for consumer_timeout_ms — or, if you don’t specify this, iteration won’t stop, and we block, awaiting new messages forever.
If you want the consumer to regularly store its offsets (i.e. how far into each topic partition you’ve read), and — upon starting — to resume at the last stored offsets, you need to pass it a group name under which to store these:
consumer = topic.get_simple_consumer(consumer_group=b"charlie",
auto_commit_enable=True)
Alternatively, don’t set auto_commit_enable and call
consumer.commit_offsets() at your discretion.
There’s more: a headline feature of PyKafka is that, like the Java client, it offers a “balanced consumer”. What’s that do, you ask?
Well, the “simple” consumer is called that because it is not aware of other consumer instances that are reading the same topic. You can assign it a subset of all the available topic partitions
parts = topic.partitions
consumer_a = topic.get_simple_consumer(
partitions=(parts[0], parts[2]))
consumer_b = topic.get_simple_consumer(
partitions=(parts[1], parts[3]))
but adding a third consumer, or removing one, will not reshuffle partitions between them. The balanced consumer is capable of just that.

Balanced consumers (aka “high-level consumers”) are a critical and uniquely differentiating feature of the Kafka system. It allows for horizontal scalability in reading high-throughput message streams. For example, if a single node can only process 1,000 messages per second, but your topic receives 10,000 messages per second, then you could use 10 balanced consumers to “shard” message consumption, with each consumer reading 1 or more partitions of data at a time. In addition to horizontal scalability, this adds high availability to your distributed consumer setups.
Balanced consumers connect to Zookeeper (which the Kafka cluster already depends upon to coordinate between brokers), enabling coordination of partition assignments between all consumers in a named consumer group. The beauty is that in PyKafka, all it takes is:
consumer_a = topic.get_balanced_consumer(
consumer_group=b"charlie",
zookeeper_connect="localhost:2181")
This gives you a consumer instance with practically the same interface as the simple consumer — except that, if you’d instantiate a consumer_b in the same group “charlie”, consumer_a would be automatically notified of this, and would surrender half of its partitions to consumer_b, and so on. And, if consumer_b disappears for some unfortunate reason, consumer_a would be assigned its orphaned partitions automatically.
Making PyKafka super fast in 2016
We were looking to make usage of Kafka and Python together just as fast as using Kafka from a JVM language. That’s what led us to develop the pykafka.rdkafka module. This is a Python C extension module that wraps the highly performant librdkafka client library written by Magnus Edenhill.
To get going with librdkafka, make sure the library and development headers are correctly installed in some conventional location (e.g. under /usr/local/). If you then rebuild (or reinstall) pykafka, setup.py will automatically detect the presence of librdkafka and build the extension module. Alternatively, you need to export some search paths to help the compiler find the librdkafka headers and lib, like so.
Now, all it takes is an extra switch when instantiating a producer or consumer:
producer = topic.get_producer(use_rdkafka=True)
consumer = topic.get_simple_consumer(use_rdkafka=True)
consumer = topic.get_balanced_consumer(use_rdkafka=True)
If the extension isn’t loadable, any of these calls will throw errors. Otherwise, that’s it, you’re good to go! You’re now using a performant C implementation of the Kafka protocol, but with the same Pythonic API!
As a side note, the librdkafka C client is actually a fully fledged client in itself, handling connections and reconnections upon cluster reconfigurations, and retrying failed requests, all automatically. In that sense, our wrapper code could have avoided communication with Kafka for itself at all. But we wanted to make the librdkafka-backed classes capable of serving as drop-in replacements for their pure-python equivalents. Thus, the librdkafka-backed consumer has been written to reuse our Python code for offset handling and consumer rebalancing, building on the C client only to handle consume() calls.
This, of course, is just a lot of talk. Let’s see about performance: what does the extra effort of hooking up librdkafka buy you?
Performance assessment
Let’s go straight for the numbers. These performance benchmarks were run against PyKafka 2.1, but should hold up for the latest PyKafka 2.4.0, as well, since no (known) performance-impacting changes happened in the meanwhile.

All these tests were run against an 8-broker Kafka cluster, running locally on a 32-core system with ample RAM (60G) and after “pre-warming” the disk cache — that is to say, we read the entire test topic into RAM before benchmarking. What you’re seeing here is a somewhat condensed summary — for more details see this topic on the issue tracker.

The consumer benefits most from the librdkafka backing, as is clear in the raw throughput numbers, and more so in the cpu load numbers. It’s worth noting also, that the gains here are conservative estimates: the throughput numbers include instance-initialization time, and the load numbers include everything from the start of the process, including interpreter and module loading.
“Why?!” you ask? I guess benchmarking is hard to do fairly, and these choices simply gave the least jittery numbers. Benchmarking already initialized consumers suggested gains for the pykafka.rdkafka flavor of anywhere between 10x and over a 40x.
It turns out, we got really nice speed-ups on producing, as well:

Not only do we get a performance boost, but we also use less CPU:

What I learned in benchmarking PyKafka is that the librdkafka speedups are certainly significant. And I had these findings confirmed by the Parse.ly team, who reported significant cluster-wide CPU savings and better throughput after putting the rdkafka-based consumers and producers into production.
—Yung-Chin Oei, contributor to PyKafka
A closing note on the Kafka community
PyKafka’s impact at Parse.ly cannot be overstated. It is core to our real-time event analytics infrastructure — which is now even available to customers as a hosted data pipeline — and it is something we will continue to invest time, code, and effort improving.

Kafka is the central “data hub” inside Parse.ly’s data center. Our real-time analytics dashboard gets its fresh data from Kafka. Kafka brokers — and PyKafka consumers — are also the source of raw data that streams to Amazon Kinesis and Amazon S3 for our hosted data pipeline product. Rather than Hadoop, we use Spark to re-process data that has been archived to S3.
With PyKafka’s recent 2.4.0 release, we feel that it is production-ready for widespread use with Kafka 0.8 and 0.9. A highlight of this release was support for Kafka 0.9’s security features via SSL — one of our top community feature requests.
We hope you enjoyed this technical deep dive on the work we’ve done to make the experience of using Kafka better for the Python community. It’s a point of pride for our backend/data engineering team that we can share our expertise — and code — to promote the adoption of this excellent technology.
As this post illustrated, PyKafka is not only a full-featured driver, but it’s also blazing fast. So, where do we go from here? Well, at Parse.ly, we’re eager to kick the tires on the recently-released Kafka 0.10, and to ensure PyKafka continues to work well with its newer features.
However, in the last couple of years working on PyKafka, we can’t help but notice that there has been quite a lot of fragmentation in the Python community around Kafka. As far as we can tell, there are three major projects as of this writing:
- pykafka, our project, maintained by Emmett Butler and Keith Bourgoin from Parse.ly, with contributions by Yung-Chin Oei (pure Python + C extension wrapper, 0.8+ support)
- kafka-python, maintained by Dana Powers, currently at Pandora (pure Python, mostly 0.9+ focused)
- confluent-kafka-python, recently released by Magnus Edenhill, who is now on the Confluent team; this was a part of the broader Kafka 0.10 release (it’s a C extension, mostly 0.9+ focused)
Each project has a different history, level of current support for Kafka, and set of features — and, of course, different APIs. This is obviously not an ideal state for the Python user community around Kafka, both those that currently have Kafka clusters in production and for those looking to adopt Kafka for new projects.
Therefore, we close this post with a call to action. If you are part of one of these communities and you have an interest in this, please chime in on our Kafka + Python community discussion issue on Github.
As for the wider Kafka community, we want to make sure Python support for this awesome stream processing technology is first-class in the years ahead. Onward to 100 billion messages per month and beyond!
—Andrew Montalenti, Emmett Butler & Keith Bourgoin, from the Parse.ly/PyKafka team
Want to work with us at Parse.ly? We are hiring backend/data engineers with an interest in stream processing, Spark, Storm, Kafka, and Python. Check out our software engineering job posting.
Want to help out in open source? You can find us on Github.
Image credits: Watercolor style Kafka diagrams come from Neha Narkhede’s talk, Demystifying Stream Processing with Kafka. Other diagrams are original to this post.