Machine learning for news: the NLP engine behind Parse.ly Currents
Does Facebook control the news? Has Donald Trump hacked the media cycle? Are search algorithms creating filter bubbles? Is outrage the only currency on social networks? These questions, and many more, are top-of-mind for the citizens of the modern internet. But, do they have the concrete data to answer any of these questions? They didn’t, until today.
Parse.ly has launched a free research tool, Parse.ly Currents, for understanding news, information, and attention flows online. It does this at a detailed and quantitative level, leveraging advanced natural language processing technology, as well as our unique view into content engagement across the web.
For the first time in history, this information isn’t locked up in the data centers of big tech behemoths, but is instead openly and instantaneously available through a live dashboard, which you can access here.
So, what is Currents, exactly? For years, Parse.ly has measured online attention through our market-leading real-time and historical analytics dashboard, Parse.ly Analytics. We work with hundreds of large content companies (including tens of thousands of journalists and editors) to measure content across thousands of high-traffic sites and apps. We help them understand what content drives readership, engagement, sharing, and loyalty. Through this work, we have built up a petabyte-scale data set which includes billions of anonymous and aggregated news reading sessions. Atop this privacy-first data set, we have now built Currents, and made it available to the world.
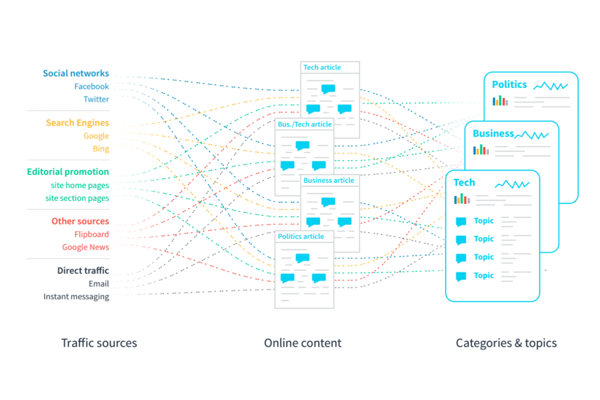
To make sense of this data, we trained algorithms to parse hundreds of thousands of digital news articles per day into well-defined categories like Politics, Tech, and Business. Our algorithms also uncover millions of unique topics, like “Donald Trump” and “Elon Musk.” The data showcases not just what the content is about, but where the traffic came from—by platform, like Google vs Facebook vs Twitter vs Flipboard, and by geography, like East Coast vs Midwest states and cities.
Further, Currents automatically groups user attention into clusters of closely-related articles, which we call Stories. These “Stories” sound deceptively simple, but are actually a novel application of natural language processing technology. For this article, we’ll do a deep dive on how we built Stories into Currents, how they are implemented under the hood, and what it all means for future artificial intelligence applications in the space of online content and news.

When human intelligence and machine learning collide
By combining the collective intelligence of billions of internet news readers with machine learning techniques applied to news and information articles, Parse.ly was able to bucket stories into topics and categories and group together articles with related storylines. Thanks to this, our system can understand sub-topics and sub-narratives.
To aid with the public’s understanding of online attention flow, Parse.ly’s dataset cuts across a number of platforms, and in so doing, acts as a check on each of them. Whereas engineers at Google have an insight into their daily web searchers, and engineers at Facebook has an insight into their daily newsfeed visitors, Parse.ly is the only company that has complete visibility across all of the largest platforms, as well as the long tail of smaller sites and apps.
We can compare the topics gaining momentum on Twitter today with the news that’s waning on Facebook, or the information very suddenly searched for on Google. We can see what political stories DrudgeReport is promoting, or not, and what lifestyle content is popular with lean-back weekend readers in aggregators like Flipboard and Google News. In short, this data is a kind of live poll of the internet and its interests.
Thanks to the our newfound understanding of the content itself via advanced natural language processing, we know this not just at the level of platforms, but even at the level of detailed topics, keywords, and real-world events.
Parse.ly’s attention analytics include not just what people search for, or what they share, but what they actually read. Not just what was published into the internet ether, with no indication of its popularity or level of engagement. But, instead, what was published and read, by thousands or even millions of people. That’s what Parse.ly can measure and reveal about internet content.
We believe this is a new category of internet attention understanding: not reading the tea leaves of search trends, nor wondering about the significance of social media monitoring, but instead true internet listening or internet-wide attention analytics.
Automatic categorization into a content taxonomy
Once we have all our data streaming in real-time and historically into a petabyte-scale warehouse where we can run arbitrary SQL queries, we can answer some interesting questions already. For example, we can rank all stories by unique visitors across the network. Or, discover stories gaining or losing steam in any given hour window. We can run these queries in seconds thanks to the warehouse’s massively parallel architecture. (Stay tuned for more about how we built this warehouse in a future blog post!)
But, we need interesting dimensions to aggregate/anonymize this traffic in a meaningful way. This is where Natural Language Processing (NLP) comes into the picture.
Our first approach here was to simply classify all of the content in our network into broad categories. For this, we used an existing content taxonomy published by the Internet Advertising Bureau, known as the IAB Content Taxonomy. A few off-the-shelf public cloud NLP APIs provide support for this taxonomy, including Google’s Natural Language API, but we found the need to take an alternative path for maximum quality against our news/article internet dataset. The end result is a system that can reliably classify content into broad categories such as Law, Gov’t, & Politics; Business; Sports; and Health & Fitness.
There are 80+ such broad categories, and a few hundred sub-categories, or “leaf categories,” in total. This does a great job of separating our content into a few logical areas that can then be further analyzed for better understanding using tuned language models.
Topic extraction with the knowledge graph
The next level of understanding is what we call a Topic, or what some NLP researchers may recognize more comfortably as an “Entity.”
The difference between a Topic and a Category is simple. A Category comes from a fixed taxonomy of content, and articles are placed into a category based on document classification rules. We try to place articles into very few categories. A Topic, meanwhile, refers to a specific person, place, thing, or concept that may appear in articles across every Category. The list of Topics is not fixed; it currently stands at millions of logical Topics, and tens of thousands in active use even in a 24-hour internet news cycle. “Elon Musk” and “Donald Trump” are Topics, but “Business” and “Politics” are categories.

To understand content about Elon Musk, our NLP engine makes use of a “knowledge graph.” This is an API with understanding of text not just from the standpoint of syntax and structure, but instead from the standpoint of actual meaning.
The most widely understood knowledge graph has been built up over years by the Wikipedia project, and its related projects, such as Wikidata. The idea here is that, in Wikipedia, we know that Elon Musk is not just a person, but also a well-known person, and one who is the CEO of several important companies, such as Tesla and SpaceX. Wikipedia has further information about Tesla and SpaceX, for example, it knows that Tesla sells products such as the Tesla Model 3 and that SpaceX is related to the aerospace and space travel industry. The kind of information you can learn about Elon Musk in this way, our NLP engine would think of as “traversing the knowledge graph”, jumping from node to node, in this case from “Elon Musk” to “Tesla” to “Model 3”.
Combined with a language model built up in code, we can reliably extract references to these important people, places, things, and concepts. So, we can tell that of the thousands of stories written about Elon Musk, some percentage are written about Elon Musk + Tesla, and some other percentage about Elon Musk + SpaceX. We can also start to learn that articles about Tesla tend to be “Business” articles, and articles about SpaceX tend to be “Science” articles. And so on.
All of these relationships are made plain and apparent in the Parse.ly Currents web interface, where you can type in any category or topic and instantly match to the ones that have traffic and content registered in our system.

Clustering related stories with word vectors
Perhaps the most novel and most recent NLP approach used in Parse.ly Currents powers our most impactful feature: Stories, which we refer to internally as “Story Clusters.” It builds on the NLP engine and time series engine described above, but goes even deeper on understanding, at a level one could truly call an artificial intelligence view of news and content.
To put it simply: a Story is a group of articles that are talking about the same thing.
They are distinguished by a few things:
- Rather than talking about specific topics (entities), they talk about specific events, which might include some number of topics. Traditional NLP can’t understand events. So, we have to approximate that using things that correlate with events that show up in language.
- They cut across categories and topics of content.
- They do not rely on any “learned” model or taxonomy of news events. It is entirely built up from word associations, and a statistical understanding of frequency of word/concept co-occurrence.
So, what is an example of an “event”? Browsing Parse.ly Currents on September 9, I found that the top story cluster is labeled, “1. Serena Williams / US Open (tennis) / Naomi Osaka.” Here, the top 3 topics are used as the label—this cluster includes all the stories about the US Open tennis match between Serena Williams and Naomi Osaka. Two example headlines from this cluster:
- “Serena Williams To Umpire: ‘I Don’t Cheat To Win, I’d Rather Lose.’”
- “It’s shameful what US Open did to Naomi Osaka.”
There was a specific event: a tennis match between two tennis pros. There were 175 identified and verified articles in the Parse.ly network written about this event; our system automatically detected and grouped these into a Story. We labeled the cluster using the top Topics, which are the tennis players themselves, and the tournament in which they play. This all happens automatically based on the language and time series traffic understanding.

Speaking of that traffic understanding: we find that 1.7 million people read those 175 articles in a 24-hour period, an astounding 10,000+ clicks per article. For context, the average article in our network gets 169 clicks in the same period!
What we are discovering here is that Stories are not distinguished by topics. So, if you looked at the top topics of the day, you’d see “Donald Trump” every day. But the reason Trump is trending is different across different days. Trump has his fingers in anywhere between 1 and 5 stories each day. And there are many other topics that also do that like Elon Musk and Serena Williams.
If you ask people, “What’s in the news today?” that’s closer to what our “Stories” feature ends up modeling. Breaking the news down into narratives (storylines, clusters of attention) matches the way people actually think about the news cycle.
Breaking down the concept of word vectors
How are we able to do this so well and effectively with so little up-front training of our algorithms?
This is the power that comes from word vectors.

Two words will have similar word vectors if they are distributed the same way in English text. That is, it doesn’t matter if two words mean the same thing; it is only important that they are semantically related, often by how they are used.
To give a stark example, Afghanistan and Iraq are latently semantically related in that they are both countries with which the US was embroiled in a long war. But they are not at all similar words, and the dictionary definition of these words (as countries) help us very little in understanding their common usage. This is where word vectors shine: by training off a large corpus of text, we can learn that Afghanistan and Iraq are “talked about” the same way, namely, in the context of war reporting or perhaps foreign policy. In this way the words are semantically linked, even if unrelated in both syntax and definition.
Our gateway to word vectors was to use fastText, an awesome open source library that provides a pre-trained model for text representation using these concepts.
Improvements over word2vec
The most popular word vector model in widespread use is word2vec. So, why did we decide to use fastText?
Well, both word2vec and fastText are conceptually possible candidates for this model of understanding. At its core, word2vec did something very clever with neural networks. From a practical standpoint, it compressed the semantic relationships between words by using neural networks, and made it so that a very large corpus of text could be turned into a small, production-usable model. If you think about compression, it’s actually a kind of learning from data. In a way, it’s a smaller representation of data, where symbols in the compressed data represent patterns in the larger source data.
By contrast, fastText does not use a neural network, but instead uses a simpler algorithm that measures word co-occurrence. But it tried to preserve the properties that made word2vec so useful in production use. The key thing is that fastText is really optimized for speed. Plus, it’s language agnostic, as fastText bundles support for 200+ languages. These characteristics made it a perfect fit for the kind of global news and content understanding Parse.ly hopes to achieve over time.
Clustering related articles with word mover distance
Though word embeddings via fastText give us some level of understanding of articles at a more semantic level, we still need a way to consider two articles “closely related” on some metric. For this, we leverage a concept called “word movers distance,” with the rather unfortunate acronym of WMD.
The concept of WMD comes from something called “optimal transport” or “earth mover’s distance.”
The canonical problem goes something like this: let’s say you have a set of mines and a set of factories, and you are the manager in charge of ensuring efficient production. How do you place the factories to optimize the transport between mines and factories? It’s a kind of variant of the rather famous “traveling salesman” problem in computer science.

In the case of words or language, we can reframe the question thusly: given an article A, how can we reposition the words in the article to be “closest” to the words in article B? The number of “semantic edits” required to transform article A to article B can be viewed as a measure of how related the two articles are. To take our earlier example, imagine article A is a piece of foreign policy analysis on the Bush years and the Iraq war, and article B is a foreign policy analysis of Obama’s handling of the Afghanistan war. We could ask the question, given a graph of word vectors and these two articles, what’s the shortest path I could take to transform article A to article B? I could change occurrences of “Iraq War” to “Afghanistan War”, and this wouldn’t move me too far in the vector space, since they are both American foreign wars (and recent ones, at that). I could change occurrences of “Bush” to “Obama”, and this also would not move me too far, since they are both US presidents, and recent ones. However, consider an article C which is a second article about the Bush Years and the Iraq War. In this case, transforming article A to C would take many fewer semantic moves than transforming article A to B. And now consider a fourth article, a recent article about the Serena Williams loss in the US Open. Well, this article, being totally unrelated, will take many more semantic moves, and thus its distance will be greater (and its relatedness lesser).
In this way, our NLP engine learns the relationships (or non-relationships) among articles in a completely unsupervised way, but in a way that models human understanding of news, information, and content quite accurately. We now cluster hundreds of thousands of such articles on a daily basis using this algorithm, and report the results in Parse.ly Currents.
In production, we generate Stories by doing the following:
- Check topic similarity using a simple information retrieval algorithm first. We use this to filter out topics to a smaller set of more “distinctive” ones, and give them a higher weight.
- Calculate the distance between every article and every other article, in the semantic vector space offered by fastText. We take the intersection over the union. This helps us understand the total weight of the set of topics shared by the article over the total weight of topics across all articles.
- Do some tuning/weighting to make the topics relevant, especially as labels for the Story.
- Pick 1-3 relevant topics to label the cluster in a way that users will understand, e.g. “Serena Williams / US Open”.
- Store the full set of articles in the cluster, their topics, and their categories.
- Assign that cluster a unique identifier to allow it to acquire new articles over the course of a 24-hour period, and to allow Parse.ly to report on it with its traffic stats.
Putting it all together: Parse.ly Currents
Our goal with developing Parse.ly Currents was to develop the world’s first transparent view of the ebb and flow of content and attention on the internet.
Making sense of petabyte-scale data, whether language or traffic data, is not easy. But, if you sign up for Currents today (it’s free!), making use of that data will seem very easy indeed. You can see all the Story Clusters trending today, which summarizes the day’s news, not from the standpoint of journalists and website operators, but from the standpoint of readers and engagement.
You can filter the traffic down to any source or platform, to understand what’s trending on Google News vs Twitter vs Reddit.

By the way: Twitter makes up a small percentage of the traffic Parse.ly sees; 23M views out of 1.3B tracked views in this one-week period, or only 1.7%! Yet, entire industries seem to be focused on analysis of the chatter on Twitter. This is a good illustration of the bias that can stem from the lack of a cross-platform view of attention.
All of this data is available to you today, and queries across billions of data points will return to your browser within seconds.
We hope you’ve learned something from this detailed discussion how the NLP brain powering Currents does its thinking every day. We’d love to hear from you and how you’re using similar NLP technology in your own projects.
Or, simply sign up and tell us how you plan to get an edge from the Currents dataset. We’re eager to hear from you. We believe Parse.ly’s approach to NLP has advanced the state of the art for news understanding in the internet era, and we’re excited for this next chapter.
The two images in the post that referenced word vectors and embeddings (using example headlines related to President Obama) each came from the academic paper, “From Word Embeddings To Document Distances”, authored by Matt J. Kusner, Yu Sun, Nicholas I. Kolkin, and Kilian Q. Weinberger in 2015. The full paper PDF is available here.