Cutting Edge AI Powering Major Update to Parse.ly’s Content Recommendations API

Updated April 2023
If you’re already a customer of the API and want to get straight to implementation, read the knowledge base article.
The majority of this post is a technical walkthrough of fairly advanced applications of artificial intelligence. If you’re interested in the machine learning, continue on below.
But first, we’re going to quickly explain what our Content API is in non-technical terms, for context.
The Parse.ly Content API is used to plug in content recommendations into web pages. For example, if visitors are reading a recipe about chocolate chip cookies, somewhere on the page the Content API would plug in a block of similar recipes: oatmeal raisin, snickerdoodle, perhaps even scones or cakes.
The point is to provide a more compelling experience for your reader, feeding them further content they’re interested in. The API boosts recirculation, keeping readers engaged with your brand, and making every piece of content more valuable.
API users can quickly and easily improve their reader experience without having to create a complex recommender product themselves, working as a key way to improve content strategy. And, compared to other tools like Outbrain or Taboola, the content you recommend is not clickbait. Taboola and Outbrain are built to drive cheap clicks off of your website. Parse.ly’s Content API keeps readers on your site by instead recommending best-fit content.
To make this visual, see an example of our API below. Notice the Related Stories block includes articles with similar topics and themes to the main article this user is reading.
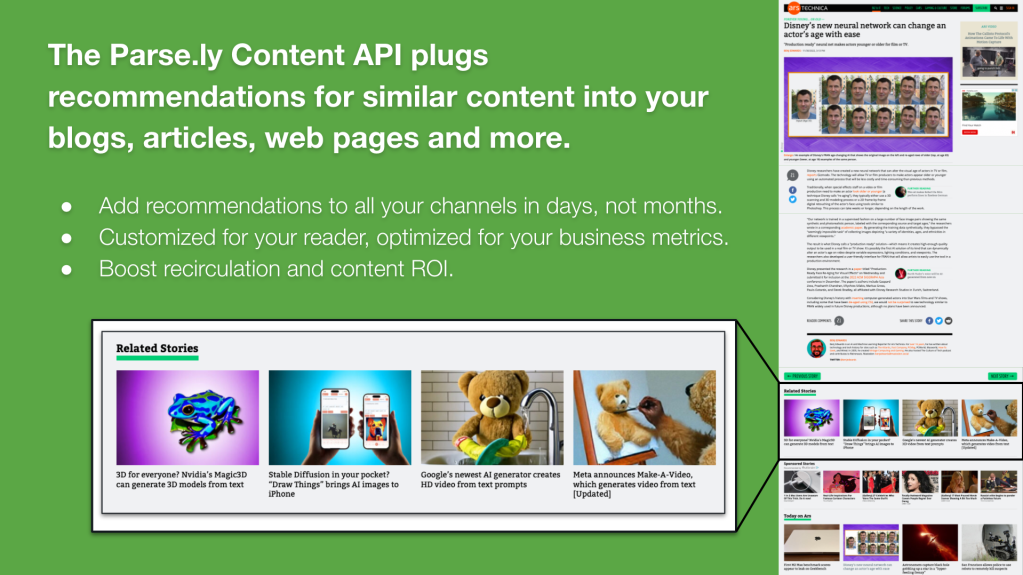
Ok, let’s get technical
Parse.ly’s recommendation engine is used to help readers discover content that’s similar to a given article. Our approach up until now has been based on lexical similarity: how many important words overlap. Our upgraded system is based on semantic similarity: how much abstract meaning overlaps. The new approach improves performance in cases where two pieces of content are about the same thing but happen to use different words.
The upgrade utilizes a recent breakthrough in the rapidly advancing state-of-the-art natural language processing: transformer models (a type of deep learning model). In particular, we use a transformer model to create an embedding to represent each document’s semantic meaning.
This upgrade is accessible under the Parse.ly API’s /similar endpoint. Our existing resource for recommendations—the /related endpoint—is still supported and remains unchanged.
What are semantic embeddings?
Our new recommendations system represents documents as points in a special space where documents that contain similar meaning are located closely together. While this space is highly dimensional—currently we use embeddings with 384 dimensions—we’ve implemented tricks to visualize it in three dimensions in the video below. In this video, each point represents a piece of content
Each time we click on a point, we see its neighbors in the original high dimensional space. As you can see, our embeddings work well because each time we click on a piece of content, its neighbors (whose titles are shown on the right) are about very similar topics.
How do we create semantic embeddings? We created a language model that can convert a piece of text into a semantic embedding. We used a standard transformer model (a sort of deep learning model) as our starting point and fine-tuned it on a large corpus of data that we labeled using an unsupervised process.
How recommendations worked previously
Previously, Parse.ly’s recommendations have been based on a fairly standard “bag of words” model. This approach essentially represents a document as a count of words. Thus, the following document:
Obama speaks to the media in Illinois.
is represented as an unordered “bag of words” as follows:
{“the”:1, “speaks”:1, “Obama”:1, “to”:1, “media”:1, “in”:1, “Illinois”:1}
There are many variants of this approach that differ in how they reduce the effect of common words (like ‘the’ or ‘as’) so that rare-but-salient words play a decisive role. After applying one of these weighting schemes, the document might look like:
{“speak”:0.1, “Obama”:0.4, “media”:0.2, “Illinois”:0.3}
This approach (especially a variant called BM25) is quite effective and remained an industry standard for 15-20 years. The bag-of-words model can be used to recommend content similar to a query document (i.e., a document of interest) by asking a database to find documents most similar to the query document. The similarity of two documents is defined as the proportion of word-weights that overlap.
ElasticSearch is a database system whose bread and butter is serving such document similarity queries both for recommender systems and search engines. Parse.ly’s /related endpoint uses ElasticSearch’s BM25 implementation in its More Like This query type. Of course, we add some additional tricks to further improve on the out-of-the box ElasticSearch, but BM25 has been at the heart of our recommendations for the last decade.
The problem: word matching is brittle
Take our first document—Obama speaks to the media in Illinois. Now, imagine we have a second document that reads:
The President greets the press in Chicago.
For anyone familiar with US politics, this document essentially says the same thing as the first document. In other words, they are conceptually similar. However, the important words in the two documents don’t match up.
Document 1: ( Obama, speaks, media, Illinois)
Document 2: ( President, greets, press, Chicago)
The different choice of words in these two documents causes the bag-of-words model to find zero similarity between these two documents, illustrating a serious problem with this approach. This example (taken from this paper) is a bit contrived, and in practice longer documents that share high semantic similarity often use many of the same words, which is why the bag-of-words model has worked quite well for so many years.
You can see how there’s room for improvement. Relying on exact word matches is a hit-or-miss affair that leaves too much to chance.
Language models to the rescue
We’ve previously written about how language models are changing everything. You can think of a language model as a huge deep learning model that has been trained on millions or billions of tasks in which it needs to predict a missing word in a document. In order to perform well on this task, the model not only learns how language works, it also learns to understand the world we describe with language. For example, the model will learn that the words Obama and President are synonyms, just like the words Senate and lawmakers.
Language models are standardly trained on this missing word prediction task, and they can take all the words in a document and transform them into wordembeddings. A word embedding represents a word as a point in a ‘semantic space’. That’s a little hard to imagine, but the key point is that words that share similar meanings are close together in this space. So if our word vectors are constructed well, then the words in our document will look like this:

In this case the language model has done a good job of creating word embeddings because words that are semantically similar (such as Obama and President, media and press) are close to each other.
Now, let’s look at the figure and try to come up with a scheme for measuring the similarity between the two documents. One approach would be to simply pair up each word from Document 1 with its most similar word from Document 2, and sum up all the distances between the pairs. This is the essence of the approach that we’ve taken in our new system. It is conceptually similar to the word mover distance approach to measuring document similarity which we have covered here.
As it turns out, current state-of-the-art language models are good at measuring the similarity between two words, but not great at measuring the similarity between two documents. We had to perform a considerable amount of research and development to implement a transformer model that could create document embeddings.
One essential trick was to use word mover distance to create labels for pairs of documents in an unsupervised manner so our model could learn how to map a document’s word embeddings into a single document embedding. But, for now, the example above gives you the high-level idea behind our approach.
What do the improvements look like?
To give you a sense of the improvement you can expect, let’s look at a concrete example from our customer, Ars Technica. We’ll use the article The road to low-carbon concrete from their homepage as a query article. We’ll then ask both our recommender systems for recommendations: the bag-of-words model (which actually serves recommendations on the page) and our new embeddings-based approach.

The query article is a long-form piece covering the huge carbon footprint of concrete production, and possible ways of shrinking that footprint. The article is quite technical, covering details of the chemistry and economics of concrete.
Looking at the content recommended by the bag-of-words model, we see that the most highly ranked recommendation is about details of the antique concrete used by the Roman Empire. This recommendation is only moderately relevant: like the query article, it goes over technical details of concrete, but unlike the query article it is not about carbon emissions and environmental impact. The bag-of-words model likely scored it high because both articles use rare words like calcium, volcanic, and clinker. The next two articles are more relevant, focusing on both concrete and carbon emissions, while the fourth article is about an innovative concrete-related idea, but not about carbon emissions.
The new embeddings-based produces stronger recommendations: the most highly-ranked recommendation is about the same topics as the query article: concrete and carbon emissions. The second-ranked article also covers concrete and carbon, and the third-ranked covers a low-emissions construction project involving lots of concrete. The fourth article here was the most highly-ranked article in the bag-of-words approach, and is only moderately relevant.
What kind of improvement can you expect?
The results we saw in the example above are a good representation of the improvements you can expect to see: more relevant articles get bumped up in rankings, and less relevant articles get bumped down. There’s often some overlap.
The improvement is most noticeable when a query article has many relevant related articles. In this case, the focus on semantic similarity can have a large impact. On the other hand, if your site has only one or two articles that are relevant to the query article, then the two approaches will often push both of those to the top of the rankings, leading to little improvement.
Try it out yourself
For Parse.ly customers who have purchased our API, it’s simple to move your requests from the /related to the /similar endpoint. The two support all the same options using the same arguments, you’ll just need to replace the word “related” with “similar”. For example, you can fire up your command line and run the following command to compare recommendations from the /similar endpoint to those from the /related endpoint:
> curl ‘https://api.parsely.com/v2/similar?apikey=[YOUR_APIKEY]&url=[QUERY_URL]’
> curl ‘https://api.parsely.com/v2/related?apikey=[YOUR_APIKEY]&url=[QUERY_URL]’
Want a demo?
If you’re not a Parse.ly customer, or don’t have the API as part of your package, request a demo to see the API in action.