Feedback Loop: How I Improved My Day-to-Day Productivity with Data
Data is enlightening, mesmerizing, and reflective. With the advent of technology, data points are much easier to harvest now. The trick in this day and age is to figure out the answers to be read from it. It is such a problem that Nate Silver’s The Signal and the Noise book touches on. This post is how I have used data to improve my workflow with two of my primary tools, git and email.
Git
When I started at Parse.ly, my experience with git was very limited in that I knew a few commands and had only learned it in my free time to fulfill a specific use case. As such, I developed bad habits but did not see them until I found a tool called git-extras.
In my limited experience, I had read some best practices with git. One of which was to commit early, and to commit often. The key idea being that without commits, you lose the advantages gained by using version control. Nowhere did I read about cleaning up commits, though. This resulted in having many tiny commits that have at its center, one change. Easily revertible and thus, I felt useful.
The result of this, is as shown with git summary:
±git summary
project : lab
repo age : 3 years, 6 months ago
commits : 1413
active : 243 days
files : 1774
authors :
284 Raymond Tang 20.1%
183 Martin Laprise 13.0%
162 Josh Click 11.5%
108 Andrew Montalenti 7.6%
106 Gabriel Barth-Maron 7.5%
98 Jenna Zeigen 6.9%
68 Dominic Rocco 4.8%
58 Mike Sukmanowsky 4.1%
58 Sam Wagner 4.1%
55 Vincent Driessen 3.9%
47 Emily Chen 3.3%
45 Zach Cimafonte 3.2%
42 dfdeshom 3.0%
41 Keith Bourgoin 2.9%
28 Matt Krukowski 2.0%
9 Charles Zhang 0.6%
7 Vihang 0.5%
4 Emmett Butler 0.3%
3 Miya Schneider 0.2%
3 talentless 0.2%
1 Jenna 0.1%
1 drocco 0.1%
1 emmett9001 0.1%
1 fastturtle 0.1%
This repository is used for intern projects and isolated code experiments, and in ~21% of the repository’s age, I had committed much more than anyone else on the team, including those who have been with the team since the beginning. I had spammed the version history to the point where it was significantly less useful as a tool.
It was then I realized I should look at how the other engineers managed to do much more with fewer commits. Originally had I thought they wrote and commit things only after they were perfect, avoiding version control, but it became apparent in that moment that, no, I had the bad habits and I needed to understand how to clean up my own commits. To that end, I learned about rebase, the details, and the secrets.
For about a year now I have been using a tool called Gmail Meter to analyze my email and describe trends from it. Some key ones popped out immediately and made me question what approach I should take with my email. For instance, I took quite a bit of time to respond to emails.
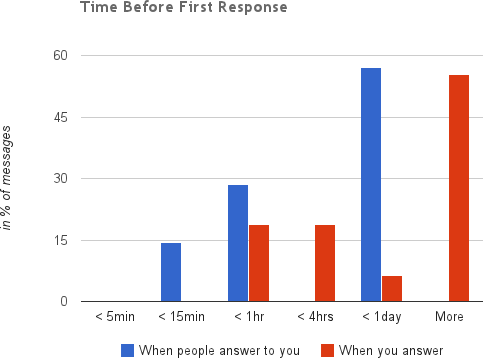
But in return, I wrote much more than I had to, being as detailed and composing well thought out emails.
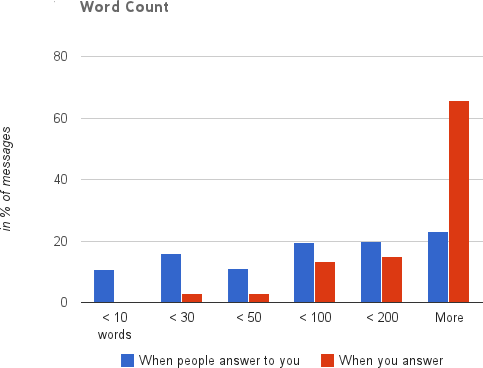
After looking at the data, and through my own interactions, I realized many would prefer more immediate responses, with the ability to follow up later on if something was not clear. This both decreased the time I spent with email, as well as allowed me to work through them much quicker, as illustrated in the following graphs whose datapoints come almost six months after the original shown above.
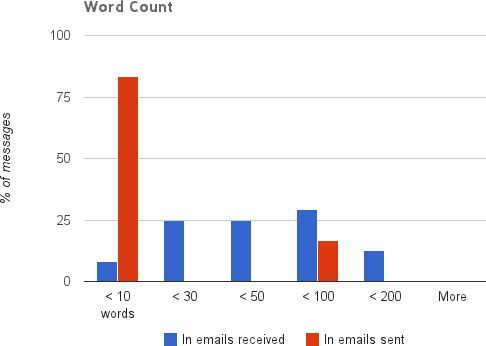
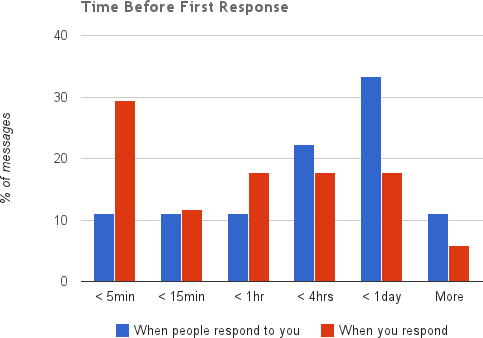
With more than 75% of my emails answered in less than 10 words, and a little more than half answered in under an hour, I would say I definitely improved my response times.
This data made for changes in the way I interacted with Git and Email, and today, data makes for large improvements in life, and even in the smallest parts of it. So how has data improved your life?
—Raymond Tang, Engineering Intern